Simplifying AI for the Future of Business.
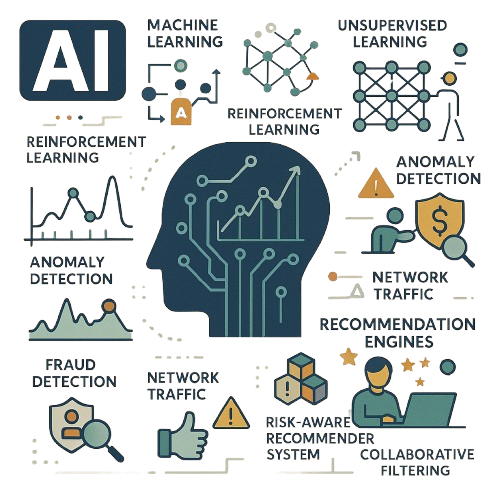
In AI [Machine Learning (supervised learning, unsupervised learning, reinforcement learning & deep learning)], we at Incryptr use advanced computational mathematics models to teach a computer to identify patterns among the domains they are trained for, to predict the trend or the future using time series analysis, classify frauds in transactions, etc. We train the model to consistently identify the anomalies. These anomalies allow you to take measures, to prevent risks in the future. These risks may be related to unusual network traffic, malfunctioning equipment, fraudulent transactions, etc. We develop Recommendation Engine that are applied to scenarios where many users interact with multiple items in diverse content environment. To build recommendation systems we use content-based filtering, hybrid recommender systems, risk-aware recommender systems and collaborative filtering methods.

We develop codes that perform automations. We at Incryptr use open-source tech-stacks to write automation codes ourselves. We design and develop attended, unattended and hybrid automations to deliver and serve diverse domains such as manufacturing, insurance, healthcare, retails, telecommunications, banking, insurance, etc.
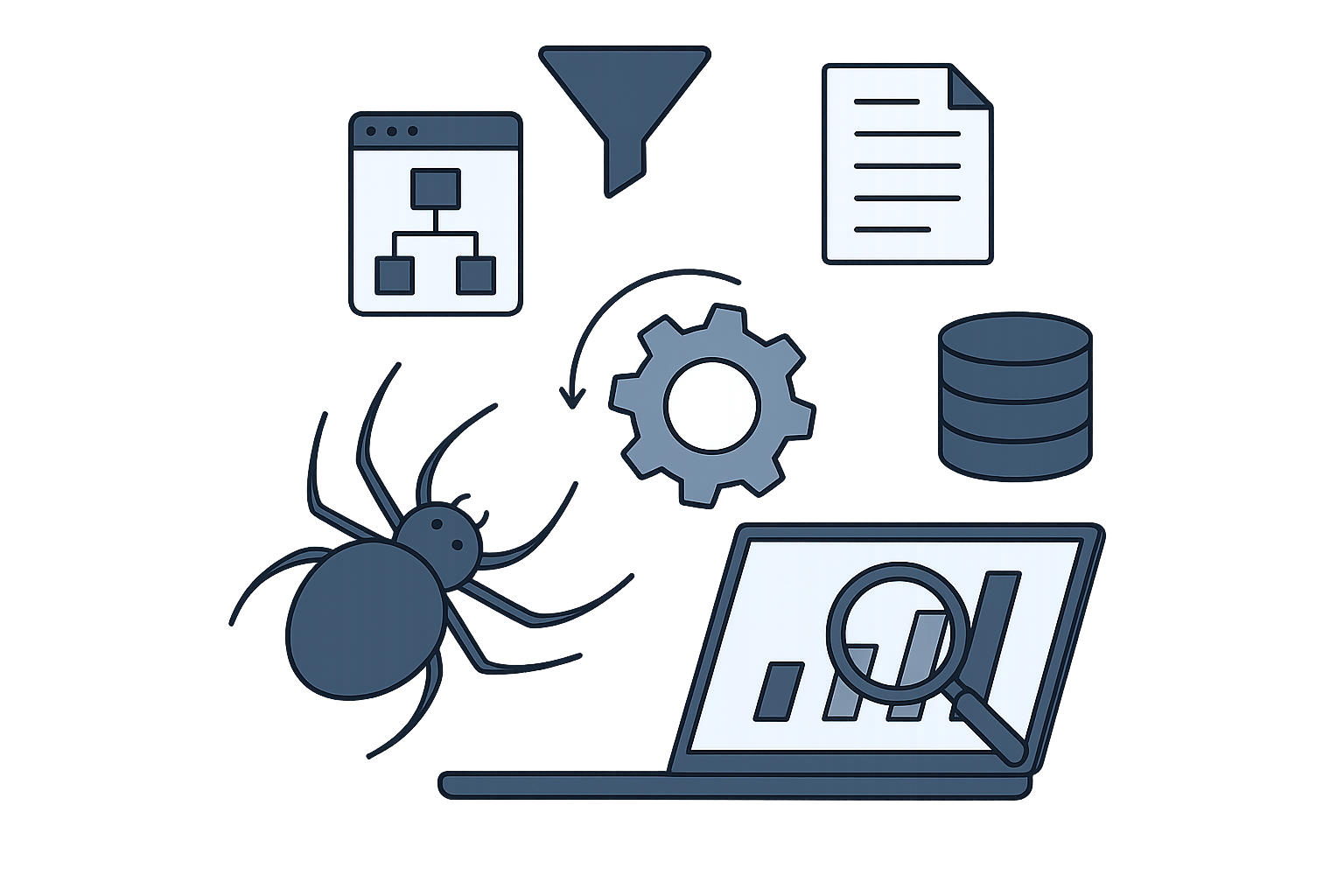
In data mining, cleaning and labelling, we design and develop spiders, scrapers and crawlers, so that they can gather data as per your business requirements. These crawlers are designed to visit the target web URLs being web pages, databases, etc. and collect and store structured, semi-structured as well as unstructured data for its future use. After gathering data, we process the data to remove impurities among it. These involve imputation, discarding null values among structured and semi-structured data, data transformations, feature engineering and extractions, filtering, etc. among all types of data types.

We understand it’s not easy to handle data, especially when it’s in large volumes, diverse in varieties and dynamic in nature. To overcome this challenge, we develop and setup architectures following the opensource tech-stack like Hadoop, hive, pig, spark, MLlib, etc. From data gathering to analysis and from applying analytical algorithms to visualizing the insights using graphs and charts, we manage the entire flow for you.
Core services under Artificial Intelligence are iterative as the precision depends on the dynamic nature of the data and the multiple hyper-parameters